A dokumentumkezelés mára a számítógépes munka legfőbb alappillérévé vált, nem csak a számviteli, vállalatirányítási területeknél létkérdés a használata, hanem gyakorlatilag minden elterjedt alkalmazási kör alapját jelenti. Nincs anélkül netes keresés, nincs zene- vagy filmkereskedelem, sőt már az egyszerű magáncímtárak is olyan tartalmak kezelését is lehetővé teszi, melyek már egyszerű fájlműveletekkel nem oldhatók meg. Gondoljunk például arra, amikor a mobilunkon, a laptopunkon vagy a számítógépünkön ugyanazon címtárból keressük ki a leveleink címzettjeit, miközben ezek a címadatbázisok már rengeteg plusz információt is tartalmaznak vagy több címtár egyesítéséből jöttek létre. Tárolunk bennük több postacímet, családi dátumokat, telefonszámokat, cégadatokat, foglalkozásokat, beosztásokat vagy éppen a feladatokhoz kötődő határidőket. Egy mai címtár gyakorlatilag mint egy mini CRM rendszer fut a háttérben telefonunkon.
A dokumentumaink elérése egy adatbázisban viszont régi, szinte a számítástechnikával egyidős feladat, már a nagygépes történelmi időkben is az egyik legfontosabb szakmai kihívást jelentette. A gyors és optimális találatot, a kívánt eredménylisták létrehozását valójában csak a rögzített adatok alapján érhetjük el, azaz a tárolt nyers adathalmaz a kereséskor információtartalommá alakul!
De hogyan? Gondolhatnánk, hogy a tartalom mennyisége megoldja a helyzetet, de ez nem igaz! A felesleges, sokszor redundáns tartalom vészesen megnöveli a méretet, ami a tárolást és az adatbiztonságot bonyolítja, ugyanakkor a nagy méret még a sebességre is negatív hatással van. A keresést persze az indexelés segítheti, gyorsíthatja, de vajon egy felesleges tartalommal feltöltött adatbázisnál mit indexeljünk? Melyik, a keresést majd segítő adatrészt használjuk fel a gyorsításhoz? Vagy minden esetben alkalmazzunk teljes körű, „full text” vizsgálatot? Százezres, milliós rekordszámnál ez nem csak elképzelhetetlen, hanem gyakorlatilag tilos is.
A mai rendszereknél ismét előtérbe kerültek az úgynevezett metaadatok, más szóval tag-ek – ezeket ne keverjük össze a programozásban, a webtervezésben használt hasonló nevű szerkezetekkel! -, melyek célja a keresésoptimalizálás és a sebességnövelés. Valójában bizonyos egyedi szavak, kifejezések gyűjteményéről van szó, melyek méretükből adódóan indexként használhatók és sok esetben nem is kell, hogy magukhoz a tételekhez kapcsolódjanak! A világot átszövő nagy adatbázis-rendszereknél már a metaadat-generálás is automatikus, speciális algoritmusokkal a szolgáltató gyárt számtalan kiegészítő adatot az általunk megadottak mellé.
A metaadatok tehát a tételekhez hozzárendelt és keresést segítő kiegészítő adatok halmaza.
A metaadat rendszer kialakítása ezért fontos és komoly feladat, már a tervezés során, például egy bevezetés előtt álló dokumentumkezelő megoldásnál a dokumentumkezelési szabályok és a folyamatok megtervezése során, ezekkel egyidőben szükséges elvégezni. Mert egy hibásan megvalósított metaadat-struktúra még a nem létezőnél is több kárt okoz… A metaadatoknak nemcsak az az adott vállalkozáshoz kell kötődnie, hanem a dokumentumkezelő rendszer kimenetéhez is, azaz ahhoz is, hogy az eredményt majd milyen célra kívánjuk felhasználni. A felvitel egyszeri és jellemzően kötött, míg a keresés időben elhúzódó és szerteágazó lehet. A rendszer kialakításánál nem tudhatjuk, hogy mondjuk három év múlva milyen szempontok szerint is kell majd a régi adatokat előcsalogatni. Tehát ne csak arra utaljanak a tag-ek, hogy mit is tárolunk, hanem adjanak segítséget ahhoz is, hogy a lekérdezések eredménye az idők során is sikeres legyen. Ez azonban előzetes szervezési, tervezési feladatokat igényel, ami viszont napjainkban sajnos egyre kevésbé népszerű.
Módszertan
A fejlesztők látva a felhasználói folyamatokra veszélyes „trehányságokat”, a mai rendszereket előkészítették a későbbi korrekciókhoz. Kétféle metaadat megoldási mód csíphető nyakon manapság:
- - kötött, előre meghatározott azonosítóhalmaz használata
- - szabadon beírható metaadat tartalom.
Az első főleg az ipari rendszereknél jellemző, ilyenkor a plusz információkat legördülő választéklistából, checkboxokkal stb. határozhatjuk meg. Jól optimalizálható ezáltal az adatbázisméret és a feldolgozási sebesség, viszont a meghatározott metaadat-tartalmon kívül a keresés eredményessége valójában nullára csökkenhet és ez csak a full text-es kereséssel javítható ki. A másik hátránya, hogy később csak az egész adatbázisrendszer módosításával változtatható meg.
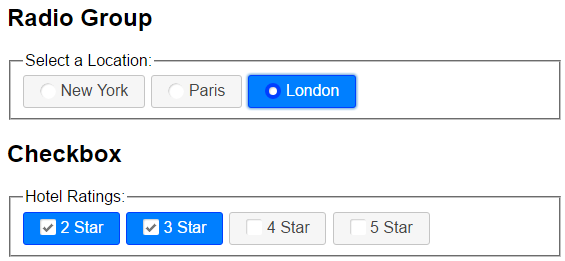
A szabadon beírható megoldás viszont a napjaink internetes oldalain és szolgáltatásain jól nyomon követhető, a blogoknál vagy a Youtube-nál beírhatunk gyakorlatilag bármennyi – a szabályoknak megfelelő formájú – keresőkifejezést. Ezeket a szolgáltatók a HÁTTÉRBEN használják fel a találat pontosításához.
Látható, hogy a két módszer használata is eredendően más: a fixen beírtaknál a keresés is ilyen módon indítható, míg a második esetben magába a keresési kifejezésbe foglalhatunk bele több adatot. Utóbbira az is jellemző, hogy mivel a neten alkalmazzuk jellemzően – tehát kapcsolódik a vékonyklienses alkalmazásokhoz is! -, a beírt metaadatok gyakorlatilag HTML (vagy XML) formátumba fordítódnak át…
A Moly.hu Arany János Toldijának képernyő és forráskód részlete:


És példa a Youtube-ról, egy Vígszinház-bemutató ajánlatának metaadat szerkezete:

A klasszikus programrendszereknél maga a kialakítás nem jelent gondot, az előre definiált metaadatoknál segédtáblák létrehozásával oldható meg a segédinformációk rögzítése, a szabadon írhatóknál pedig elég egy adattábla is, ahol az egyes tételeket egy-egy egyedi azonosítóval írhatunk le, majd ezek kerülnek – fizikailag vagy logikailag - bele az adatbázisunk rekordjaiba. A gond a keresésnél jelentkezik. A kötött metaadat szerkezetnél a keresés előre kódolható, a másik esetben azonban a keresést végrehajtó utasításnál előbb össze kell állítani magát a keresési adatsort, hiszen nem tudjuk előre, hogy hány kifejezést kell figyelembe vennünk, mennyit ír be a felhasználó.
És azonnal látni fogjuk a hátrányt is, miközben nem kerülhetjük meg a tényt sem, ez a módszer a divatos, az általános napjainkban…
Előnyből hátrány
A szabadon beírható keresőszavak esetében a tételek rögzítésekor semmiféle előírás nincs a használható szavakra nézve, még ugyanaz az adatrögzítő is garantáltan szinonimákat fog használni, hiszen fél évvel később miért emlékezne egy már korábban használtra. Segíthetünk a már létező szavak (Autocomplete funkció) megjelenítésével, de ez pár tucat szó fölött kezelhetetlenné teszi az adatrögzítést. A nagyobb adathalmazok esetében ezáltal nemcsak rengeteg hasonló – tehát felesleges - azonosító kerül rögzítésre, hanem roppant mód lerontja a találati pontosságot. A találati listák esetében pedig garantált, hogy nem lesz egybegyűjtve az összes szükséges tétel! Egy fővárosra kiadott keresésnél a program honnan tudja, hogy a Budapest, Bp, Bpest ugyanazt jelenti. Persze a szakmai, így a számviteli rendszereknél is szakkifejezéseket használnak, a rögzítő és a lekérdező is valójában ugyanazon halmazhoz tartozók, de még ebben az esetben is gyakori a pontatlanság.
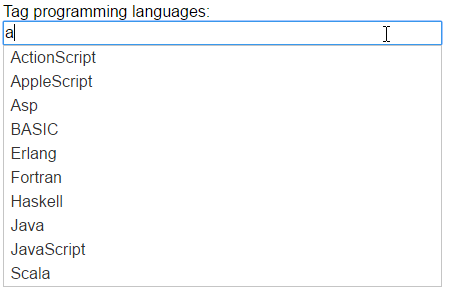

Az előre megadott módszernél mindez teljes egészében kiküszöbölhető, hiszen a megadott választék azonos a rögzítés, illetve a lekérdezés során és a szűrés elvégezhető a mára már elfeledett logikai operátorokkal, azaz a programozása is egyszerű és kényelmes. Itt meg az a baj, hogy csak egy ésszerű határig lehet előre keresőszavakat definiálni, mert magát az adatrögzítést tesszük szinte lehetetlenné és a képernyők kialakítása is nagyon hamar átláthatatlanná, kezelhetetlenné válik. Sokat segíthet ezen, hogy a rögzítésnél már létrehozunk a tételekre jellemző kifejezésgyűjteményt és ezeken belül egy behatárolható választéklistával már elég pontos kategorizálás végezhető el. És ha általános keresésre van szükség, akkor még mindig ott a teljes tartalmú keresési módszer.
A kettő párosítása az esetek döntő részében ideális megoldást jelent, könyvtárakban, archívumokban ez a módi a jellemző, a fix metaadat-szerkezettel évjáratokra, kiadványokra, szerzőkre stb. szűrhetünk, míg a beírva mondjuk a „Kennedy-gyilkosság” szöveget, a teljes archívumból válogathatjuk össze az ennek megfelelő tételeket.
Divat vagy hatékonyság? Mindkét esetben pénzkérdés…
A két módszerre és eredményességére jellemző példa a Google kereső működése. Amikor honlapot terveztetünk cégünknek, akkor annak leírásába célszerű minél több keresőkifejezést szerepeltetni - persze ezek csak valamilyen szinonimái a másiknak -, miközben ha fizetett hirdetést rendelünk a cégtől, akkor ez a módszer gyakorlatilag nulla eredmény fog hozni. Miközben viszi a befizetett pénzkeretünket. A sok hasonló kifejezés ugyanis rengeteg téves találatot eredményez, pontosabban a találat pontos, de az érdeklődő valójában nem azt keresi. Ha még fizetünk is a találatok után, akkor csak a pénzünk fogy, hasznos kapcsolat nem jön létre egy érdeklődővel. Szóval a webes kereséseknél még hasznos a sok metaadat, de ha mobilra váltunk, fizetett hirdetéssel is élni akarunk, akkor már csak a pár darab és fokozottan ránk utaló szót érdemes használni. Ha nincs felesleges találat, nincs felesleges pénzkidobás sem.
A metaszavas keresésoptimalizálás tehát nélkülözhetetlen a dokumentumkezelőkben, anélkül gyakorlatilag nem is érdemes ilyen rendszert használni. De hogy a hatékonyságra (azaz az előre tervezésre, a pontos definíciókra, a szigorú adatmegadásra) tesszük a hangsúlyt vagy a roppant trendi, de valójában csak speciális területeken eredményes szabadszavas módszert választjuk, már megfontolást igényel.